-
6. KMP, Knuth-Morris-PrattCS/Alogrithm 2020. 6. 19. 18:30
대표적인 문자열 처리 알고리즘 중 하나인 KMP를 소개해보려 합니다.
알고리즘 이름은 해당 알고리즘을 고안한 분들의 이름을 따서 만들어졌습니다.
문자열 관련 알고리즘 또한 다양한데요.
해당 알고리즘은 문자열 A를 기준으로 문자열 B에 포함된 개수를 찾는 것이 핵심입니다.
해당 알고리즘의 대표 문제인 찾기(백준 1786번)에도 관련 내용에 대한 설명이 나와 있습니다.
알고리즘을 이해한 후에 해당 문제도 한번 풀어보시면 좋을 것 같습니다.
간단한 예시를 들면 아래와 같은 문자열에서 문자열 A가 총 몇 개 포함되어 있는지 찾는 문제입니다.
문자열 B: Apple is not green Apple but, red one.
문자열 A: Apple
역시나 눈으로 찾긴 쉽습니다. 간단하게 2개가 바로 보이네요.
컴퓨터에게 알려주려면, 이렇게 짧은 문자열의 경우엔 중첩 반복문을 통해서 찾아낼 수 있습니다.
String A = "Apple"; String B = "Apple is not green Apple but, red one"; int bLen = B.length(); int aLen = A.length(); int count = 0; for (int i = 0; i < bLen; i++) { boolean hit = true; int index = i; for(int j = 0; j < aLen; j++) { if(A.charAt(j) != B.charAt(index++)) { hit = false; break; } } if (hit) count++; }약식으로 후다닥 짰는데 일단 결과는 나왔습니다. ㅎㅎ
N: 비교할 문장의 길이(A)
M: 비교 당하는 문장의 길이(B)라고 할 때
중첩 반복문을 돌리면 O(N*M)의 복잡도를 가지고, 답을 구할 순 있습니다.
하지만, N, M이 조금만 커지면 바로 시간 초과가 발생하겠죠.
KMP 알고리즘의 목적은 N, M의 값이 큰 경우에도 답을 낼 수 있도록 유도하는 것이 목적입니다.
시간 복잡도는 O(N+M) 입니다.
우선 알고리즘을 어떻게 운용할 것인지 대략적인 설명 후 코드에서 살펴보도록 하겠습니다.
우선 실패 함수라는 것이 필요합니다.
실패 함수는 1차원 배열을 반환 값으로 갖고 배열에 들어있는 값은 다음과 같습니다.
'어떤 문자열 S의 부분 문자열에서 prefix와 suffix가 같은 최대 길이'
(그림으로 설명드리는 것이 편할 것 같아 그림을 가져왔습니다.)
실패 함수에서 반환하는 배열을 F라고 하고 그때 배열 F의 인덱스를 fidx로 지정하겠습니다.

그림 1. AABAABBA F[] 간략하게 설명드려보면, 문자열 0번부터 N번까지 부분 문자열을 사용합니다.
A -> AA -> .... -> AABAABBA 이렇게요.
그리고 각 부분 문자열마다 앞(prefix), 뒤(suffix)의 동일한 문자열의 개수를 찾습니다.
해당 값들이 F[]에 저장됩니다.
위의 작업을 완료하면 실패 함수를 반환합니다.
Failure.java
private static int[] failure(char[] words) { int j = 0; int[] F = new int[words.length]; for (int i = 1; i < F.length; i++) { // matching prefix & suffix size while (j > 0 && words[i] != words[j]) { j = F[j - 1]; } if (words[i] == words[j]) F[i] = ++j; } return F; }코드만 보면 조금 불편하니, 동작을 그림으로 보여드리겠습니다.

그림 2. 초기 상태 
그림 3. 반복문 1회 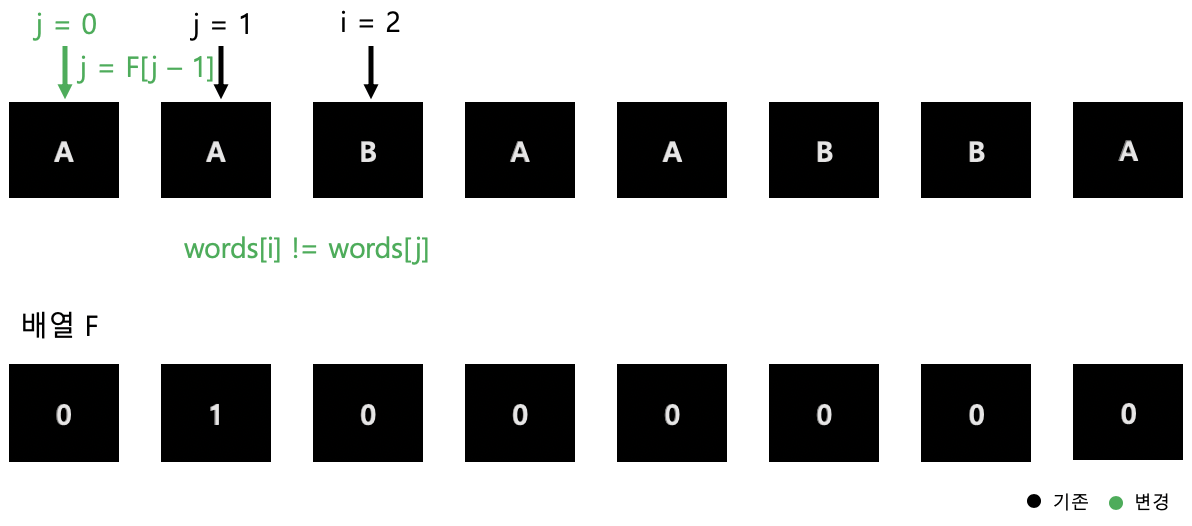
그림 4. 반복문 2회 
그림 5. 반복문 3회 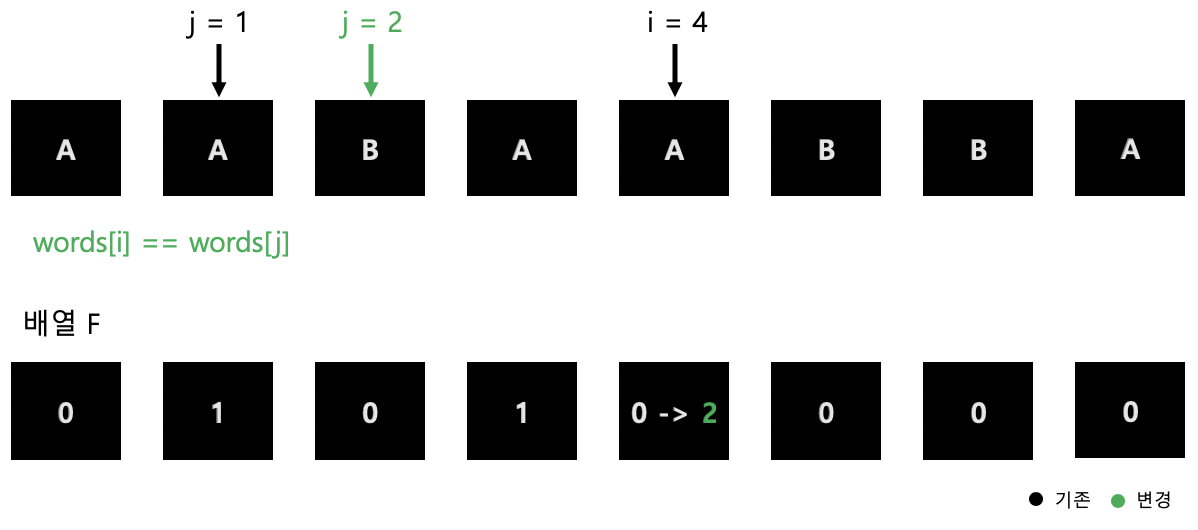
그림 6. 반복문 4회 이렇게 반복적으로 i, j가 가리키는 값이 같다면 F 배열을 채워주고 다르면 넘어가는 식으로 작동합니다.
결과적으론 위에 표로 그려둔 F 배열과 같은 값이 전체적으로 채워지게 됩니다.
Failure.java (test)

그림 7. AABAABBA 출력 결과 결과를 보시면 동일하게 나온 것을 확인할 수 있습니다.
그런데, 실패 함수가 왜 필요한 것일까요?
필요한 이유는 KMP 알고리즘의 특징 중 하나라고 생각하시면 되는데요.
실패 함수를 통해 일치하는 데이터의 위치를 찾고 필요없는 데이터 확인을 건너뛰기 위함입니다.
즉, 일치한 값을 저장해 두고 그에 따라 이미 계산된 값은 넘겨주기 위함이죠. 가지치기 느낌이네요. :)
위에서 사용했던 문자열을 가져와서 해당 문자열에 AB라는 문자열이 몇 개나 등장하는지 찾아보겠습니다.
눈으로 보니 2개가 딱 보이네요. 이제 코드를 구성해서 찾아내 보겠습니다.
String A: AABAABBA
String B: AB
그전에 F 배열을 어떻게 이용해서 답을 찾을 수 있을까요?
- Failure 함수 때와 같이 다른 값이 등장한다면 j = fail[j - 1]로 초기화
- 1) 에서 j번째 단어는 달랐으므로 (j - 1)번째 까지 맞았다 라고 설정.
- 같은 값이 등장하면 j값을 증가, -> 즉, 현재까지 몇 개의 단어가 맞았는지 체크
- j의 값이 문자열 B의 길이. 즉, (B.length - 1) 만큼 도달하면, 문자열 하나를 찾았으므로 (결괏값 + 1) 한 후 j = F[j]
- F[j]로 변경하는 이유: 'BAABBAAB'라는 문자열에서 'BAAB'를 찾는다고 가정
- F[] = {0, 0, 0, 1} 이고, j = 3 일 때 j = F[j]가 되며, 이는 1의 값을 가짐
- 즉, BAABBAAB에서 F 배열을 통해 이미 BAAB 양 쪽은 suffix, prefix가 동일함을 뜻하고 'AA' 구간을 건너뛸 수 있음 (중요)
- -> 몇 개의 데이터가 일치했는가를 이용하는 파트라고 보시면 되겠습니다.
- 1) ~ 4) 반복
단어가 계속 다르다면 계속 2)의 작업이 반복됩니다.
KMP.java
public class Main { public static void main(String[] args) { String A = "AABAABBA"; String B = "AB"; System.out.println(KMP(A.toCharArray(), B.toCharArray())); } private static int[] failure(char[] words) { int j = 0; int[] F = new int[words.length]; for (int i = 1; i < F.length; i++) { // matching prefix & suffix size while (j > 0 && words[i] != words[j]) { j = F[j - 1]; } if (words[i] == words[j]) F[i] = ++j; } return F; } private static int KMP(char[] t, char[] p) { int result = 0; int[] F = failure(p); int j = 0; for(int i = 0; i < t.length; i++) { while (j > 0 && t[i] != p[j]) { // not matching j = F[j - 1]; } if (t[i] == p[j]) { // matching if (j == p.length - 1){ j = F[j]; result++; } else { j++; } } } return result; } }글로만 보면 역시나 확 와 닿진 않으니 그림으로 어떻게 동작하는지 먼저 보겠습니다.

그림 8. 반복문 1 ~ 2 완료 - 1번째 반복문: i, j 모두 0 인 경우는 서로 같습니다. j++
- 2번째 반복문: i == 1, j == 1인 경우, 보시다시피 다르기 때문에 j = F[j - 1]로 초기화해줍니다. j = 0
- 0으로 초기화하고 밑으로 가니 i == 1, j == 0이고, 이 또한 서로 같기 때문에 j값이 증가합니다. j++

그림 9. 반복문 3 완료 - 3번째 반복문: i == 2, j == 1인 경우, 둘 모두 B로 같은 값을 가집니다. j++
- j == B.length - 1의 값에 도달했습니다. result++, j = F[j] = 1

그림 10. 반복문 4 완료 - 4번째 반복문: i == 3, j == 1인 경우, i는 A이지만, j는 B로 다르기 때문에 j = F[j - 1] 초기화. j = 0
- 0으로 초기화된 후 아래 조건문에서 둘 다 A로 같으므로 다시 j 증가. j++

그림 11. 반복문 5 ~ 6 완료 - 5번째 반복문: i == 4, j == 1인 경우, 서로 다름. j = F[j - 1] = 0
- 위와 같이 0으로 초기화 후 A로 같음. j++
- 6번째 반복문: i == 5, j == 1인 경우, B로 같으며 j == B.length - 1에 도달. result++, j = F[j] = 1
이와 같은 방식으로 진행되며, 최종적으로 2의 값을 반환합니다.
KMP.java 결과
그림 12. 결과 동시에 진행되는 동작들이 많아 그림상 생략된 부분도 있고, 자세히 보지 않으면 헷갈릴 수 있습니다.
저는 처음에 문자열 길이 8, 4 자리 두 개로 직접 손으로 그려봤는데, 그게 이해가 빠르고 좋았습니다.
추천드리구요. ㅎㅎ
특히, 제가 while문의 연속적인 동작에 대한 설명을 따로 안 드렸는데 간단한 부분이라 굳이 보여드리진 않았습니다.
시간 복잡도는 failure 함수 + KMP 반복문을 통해 도출 가능합니다.
우선 failure 함수나 KMP 반복문은 동일하게 동작함을 아실 수 있습니다.
failure 함수에서 반복문 자체가 아닌 j의 움직임만 체크해보시면 최대 words 배열 길이만큼만 증가하거나 감소합니다.
따라서 선형 시간을 갖는다는 것을 유추할 수 있습니다.
위의 예제는 매칭 되었을 때 문자열 길이가 2인 경우라 잘 느껴지지 않네요.
좀 더 긴 길이의 다양한 문자열을 사용해보시면 확 와 닿으실 것 같습니다.
추가적으로 좀 더 긴 문자열을 넣어서 결과를 참고용으로 올려드립니다.
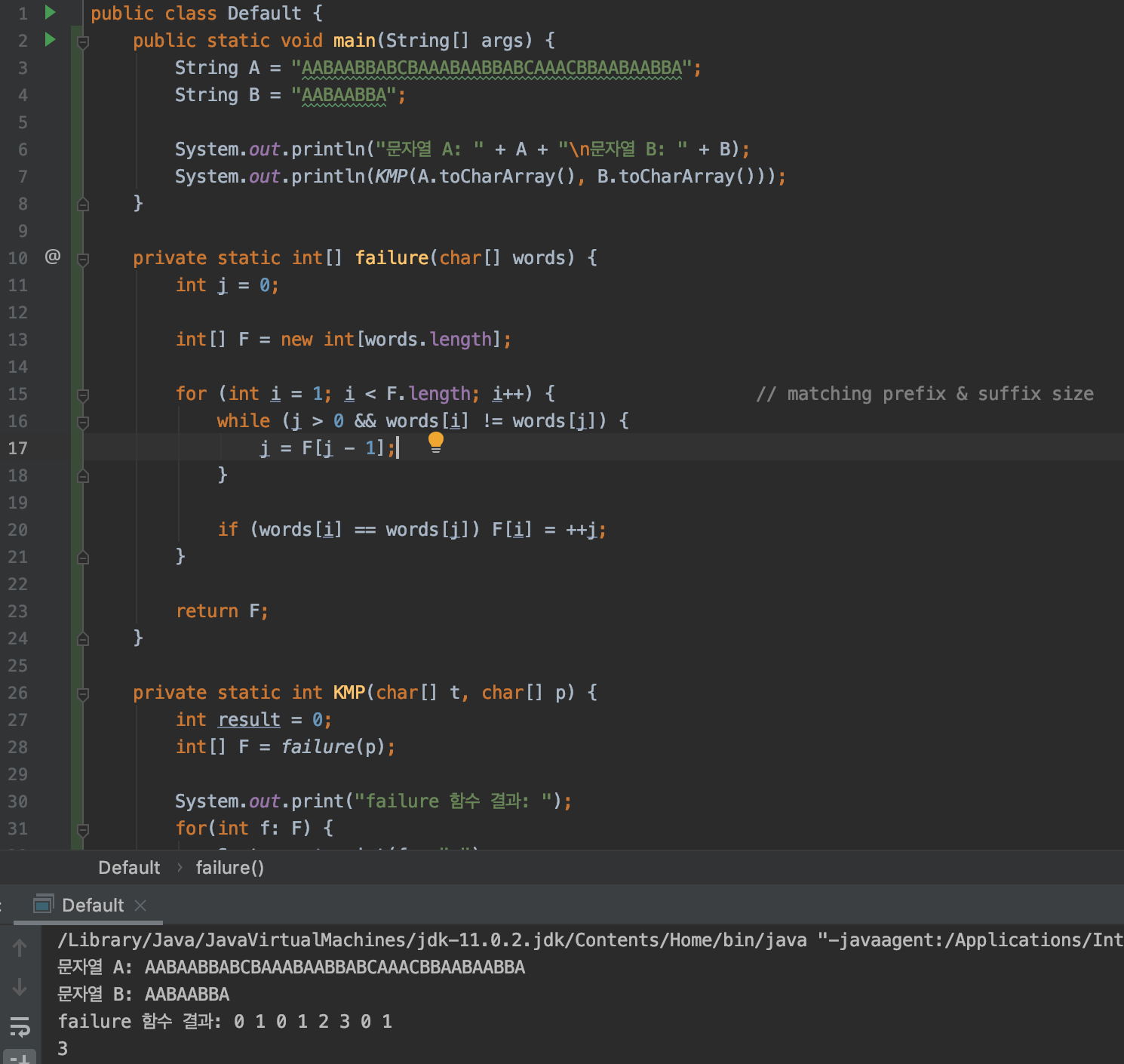
그림 13. 예제 결과 문자열 B는 위에 설명하는 데 사용한 문자열을 사용했습니다.
질문이나 틀린 부분 있으면 댓글 달아주세요!
빠르게 답변이나 보완하도록 하겠습니다. 감사합니다.
반응형'CS > Alogrithm' 카테고리의 다른 글
8. Huffman's Code (허프만 부호화) (0) 2020.11.18 7. Greedy (그리디 알고리즘, 탐욕법) (0) 2020.11.17 5. LCA, Lowest Common Ancestor (최소 공통 조상) (0) 2020.03.05 4. Disjoint-set, Union-find (서로소 집합) (0) 2019.05.22 3. Eratosthenes' Sieve (에라토스테네스의 체) (0) 2019.03.26