-
4. Disjoint-set, Union-find (서로소 집합)CS/Alogrithm 2019. 5. 22. 22:05
SW 마에스트로 합격 이후로 정신없이 지내서.. 이제야 글 하나를 씁니다.
올해는 이 글이 마지막 글이 될 것 같아요...
(그래도 가능하면 관련 문제에 대한 글 한두 개 정돈 쓰도록 하겠습니다.)
오늘 설명드릴 알고리즘은 서로소 집합입니다.
Union-find, Disjoint-set 모두 서로소 집합을 의미하는 용어인데요. 후자가 좀 더 의미에 와 닿는 것 같아요.
사실 이 알고리즘에 대한 설명을 쓸지 말지 고민을 많이 했습니다.
제가 가장 좋아하는 알고리즘(이를 응용한 MST 포함해서요) 중 하나인데요.
'이렇게 글을 쓸 정도로 잘 알고 있나?'라고 생각을 해보면 그건 아닌 것 같아서요.최대한 자세하게 적도록 해볼게요.
DisJoint-Set, Union-find
말 그대로 서로소 집합입니다.
서로소란 수학에서 서로 1을 제외한 공약수를 갖지 않는 수들을 의미합니다.
수식으로 나타내면 아래와 같습니다.
A ∩ B = ø
가령, 소수들은 1을 제외하면 각각 서로서로가 공통된 약수를 갖지 않는 서로소인 셈이죠.
이런 서로소들끼리의 집합을 서로소 집합이라고 표현합니다.
수학에서의 정의는 저렇지만, 사실은 서로소의 집합이기 때문에 각각의 집합 내부의 원소들은 어떤 공통점을 가지게 됩니다.
아직은 크게 와 닿지 않으실 텐데, 예를 들어 설명해보겠습니다.
아래와 같이 여러 도형들이 있다고 가정해볼게요.
이 도형 하나하나를 원소라고 생각하시고 봐주세요. 원소를 구분짓는 방법은 여러 가지가 될 수 있겠죠?
사람, 사물, 숫자 등등..
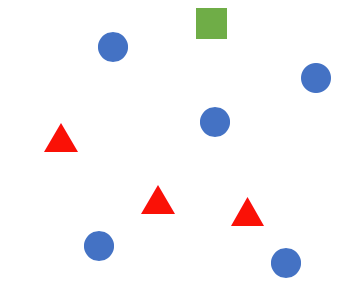
어떤 공통점이 보이시나요?
같은 모양과 색을 가진 도형들이 하나씩 있네요. 이 색 또는 모양이 이들을 집합으로 만들어주는 기준이 됩니다.
그리고 그 기준에따라 묶어주면 아래와 같이 집합이 형성됩니다.

초등학교 수학시간 같네요..이렇게 묶였습니다. 묶여있으니 집합이겠죠? 그리고 이렇게 묶인 집합들은 서로에 대하여 서로소가 되었구요.
이게 바로 '서로소 집합'입니다.
이제 서로소 집합이 무엇인지 감은 잡히셨을 텐데, 이를 코드로 어떻게 구현할지 이에 대해서 얘기해볼게요.
우리는 각 배열에 어떤 값들을 넣고 이 값들을 통해 해당 배열의 값이 집합인지 아닌지 판단하도록 유도할 겁니다.
각 배열에 같은 값을 넣고 비교를 하면 가장 간단하게 구분이 가능합니다.

집합의 리스트는
- 집합 1: {4, 5, 6}
- 집합 2: {0, 1, 3}
- 집합 3: {2}
- 집합 4: {7}
이렇게 간단하게 나눌 수 있습니다. 크기도 잘 보이네요.
하지만 컴퓨터가 이를 알기 위해선...
각 배열에 들어있는 값들 1 ~ N 마다 배열 크기 M 만큼 돌려야 하니 최대 O(NM)의 시간 복잡도를 가집니다.
효율성이 매우 떨어지죠.
그래서 우리는 앞으로 parent라는 배열과 merge, find 메소드 두 개를 가지고 어떻게 집합을 표현할지 알아보겠습니다.
위에 예시로 들었던 배열을 'int[] parent'라고 가정하고 코드부터 구현해 볼게요.
- parent 배열은 해당 원소의 부모를 찾아갈 수 있도록 하는 배열입니다.
- 해당 배열은 각 메소드마다 계속 쓰이므로 static 변수로 올려두고 씁니다. (
개인 취향) - 자식 원소는 배열의 값으로 부모의 인덱스를 저장하고, 부모 원소는 자신의 배열에 집합의 크기의 음수 값을 저장합니다.
- 해당 배열은 각 메소드마다 계속 쓰이므로 static 변수로 올려두고 씁니다. (
- find는 어떤 원소의 부모 인덱스를 찾는 메소드입니다.
- merge는 서로 공통점을 갖는 원소끼리 묶어주는 메소드입니다.
- 이미 묶여있다면, 부모 인덱스 값 비교를 통해 바로 리턴해줍니다.
우선 초기 parent 배열은 아래와 같이 구성됩니다.
init 메소드
private static void init(int n) { parent = new int[n]; for(int i = 0; i < n; i++) { parent[i] = -1; } }크게 이상할 게 없죠..?
시작엔 모두 다 다른 집합으로 존재하기 때문에 해당 집합의 크기의 음수 값, 즉 -1이 각 배열마다 초기화됩니다.
다음은 find 메소드입니다.
여기서 왜 우리가 음수 값을 처음에 초기화시키는지 알 수 있습니다.
find 메소드
private static int find(int x) { if(parent[x] < 0) return x; return parent[x] = find(parent[x]); }왜일까요?
양수가 들어가 버리게 되면, 어떤 게 부모 원소이고 어떤 게 자식 원소인지 찾을 수 없게 됩니다. (ㅜㅜ)
물론 다른 방법들도 많으니 편하신 코드를 찾아 쓰시길 추천합니다.
위의 코드에 대한 구조를 보면,
해당 배열의 값이 음수라면 그 원소 기준으로 다른 원소들이 묶였으니 그 배열의 인덱스, 즉 부모의 번호를 반환합니다.
음수가 아니라면 해당 인덱스는 자식 원소의 번호입니다. -> x번째(자식 원소)의 부모의 인덱스 번호를 통한 재귀 호출을 합니다.
동시에 그 값을 parent[x]로 할당하면서 말이죠.
이 작업을 '탐색 거리를 압축시킨다'고합니다.
예시를 들어 간단히 설명해보겠습니다.
아래에서 괄호 내부는 자식 원소의 인덱스 옆의 값은 최종 부모 원소의 인덱스를 의미합니다. ([자식idx]: 최종부모idx)

이러한 상황을 만들어 내려고 합니다. 처음부터 이렇게 구성되진 못하겠죠.
왜냐면 각 merge 메소드로 들어오는 값들은 천차만별인데요.
따라서 서로서로 엮여는 있지만 부모 배열을 제외하곤 모두 바로 상위의 배열의 인덱스만 값으로 가지게 됩니다.
이렇게 되면 최종 부모 배열을 찾는데 매우 시간이 오래 걸리기 때문에 이런 식으로 압축을 해줍니다.
그래서 과정을 살펴보면,
- 우선 x값으로 4가 들어갑니다.
- 해당 원소의 데이터는 2이기 때문에 'return parent[4] = find(2);'가 실행됩니다.
- 다시 parent[4]의 값을 통해 find(2)가 실행됩니다.
- parent[2]의 값도 0과 다르기 때문에 'return parent[2] = find(0);'이 실행됩니다.
- 마지막으로 parent[x] < 0 즉, 위에 예시에 따르면 'parent[0] == -6' 이므로 이제 x를 계속 반환해줍니다.
- 역순으로 parent[2] = 0, parent[4] = 0 ....
이렇게 바꿔두니까 앞으로 부모 배열을 찾아 집합의 크기를 알아볼 때 매우 빠르게 찾을 수 있습니다.
(디버깅도 편하구요.)
그래서 find 메소드는 위와 같이 구성되었구요.
이제 merge 메소드를 봅시다. merge 메소드는 아래의 두 기능을 실시해줍니다.
- 서로서로 엮여는 있지만 부모 배열을 제외하곤 모두 바로 상위의 배열의 인덱스만 값만 가지게 됨
- 부모 배열에는 해당 집합의 크기가 들어감
코드를 보면 크게 어렵진 않습니다.
merge 메소드
private static void merge(int x, int y) { x = find(x); y = find(y); if(x == y) return; if(parent[x] < parent[y]) { parent[x] += parent[y]; parent[y] = x; } else { parent[y] += parent[x]; parent[x] = y; } }상당히 직관적이죠...? ㅎㅎ
- x, y가 서로 같은 부모를 갖는지 확인합니다.
- 공통점을 가진 원소들인데 서로 다른 부모라면 엮어주겠지만 이미 묶여있다면 할 필요 없으니 바로 반환합니다.
- 서로 묶여야 하는 경우 x, y는 각각 find 메소드를 통해 자신의 부모의 인덱스를 받아왔습니다.
- 그리곤 해당 배열의 값이 작은 배열로 합쳐줍니다. (집합의 크기가 합쳐지는 것이죠.)
- 값이 작다는 것은 집합의 크기는 크다는 뜻입니다.
- 큰 집합으로 묶어줘야 find 메소드에서 부모 인덱스를 새로이 할당할 때 조금이라도 비용이 덜 들 테니까요.
이렇게 해서 최종 코드는 아래와 같습니다.
Distjoint-set.java
import java.io.BufferedReader; import java.io.InputStreamReader; import java.util.StringTokenizer; public class Main { private static int[] parent; public static void main(String[] args) throws Exception{ BufferedReader br = new BufferedReader(new InputStreamReader(System.in)); int N = Integer.parseInt(br.readLine()); init(N); int M = Integer.parseInt(br.readLine()); while(M-- > 0) { StringTokenizer st = new StringTokenizer(br.readLine()); int x = Integer.parseInt(st.nextToken()); int y = Integer.parseInt(st.nextToken()); merge(x, y); } for(int i = 0; i < N; i++) { System.out.print(parent[i] + " "); } } private static void init(int n) { parent = new int[n]; for(int i = 0; i < n; i++) { parent[i] = -1; } } private static int find(int x) { if(parent[x] < 0) return x; return parent[x] = find(parent[x]); } private static void merge(int x, int y) { x = find(x); y = find(y); if(x == y) return; if(parent[x] < parent[y]) { parent[x] += parent[y]; parent[y] = x; } else { parent[y] += parent[x]; parent[x] = y; } } }위와 같이 작동하게 된다면 parent 배열은 아래와 같이 구성됩니다.
(사실 부모 원소가 어떤 배열로 지정될진 모르지만요.)

실행 결과

약간 아쉽게도 4번 부모 배열이 5번이 부모인 것으로 잡혔네요. ㅎㅎ
이는 입력에 따라 달라지기 때문에 크게 신경 안 쓰셔도 될 부분이라 생각됩니다.
그리고 사실 위의 그림처럼 배열에 값을 넣고 돌려도 됩니다.
하지만, 일반적으로 문제에선 저런 식으로 나오기 때문에 제가 직접 입력을 정해서 넣었습니다.
일반적으로 Disjoint-set의 시간 복잡도는 크기: N, 연산수: M 일 때 O(Mlog∂(N))이라 합니다.
여기서 ack(∂)는 아크만 역함수를 뜻하는데요. 거의 상수 O(1)에 근접합니다. (사실 이 함수는 너무 어려워서 이해를 못했습니다.)
그리고 logN의 경우엔 숫자가 아무리 커도 대부분 2 자릿수에 머물기 때문에 약 O(M)의 시간 복잡도를 가진다고 생각하시면 될 것 같아요.
네, 여기 까집니다.
질문이나 틀린 부분 있으면 댓글 달아주세요!
빠르게 답변이나 보완하도록 하겠습니다. 감사합니다.
반응형'CS > Alogrithm' 카테고리의 다른 글
6. KMP, Knuth-Morris-Pratt (0) 2020.06.19 5. LCA, Lowest Common Ancestor (최소 공통 조상) (0) 2020.03.05 3. Eratosthenes' Sieve (에라토스테네스의 체) (0) 2019.03.26 2 - 3. DFS 예제 (1260번: DFS와 BFS), DFS 응용 (0) 2019.03.09 2. Breadth/Depth First Search (BFS/DFS: 너비/깊이 우선 탐색) (0) 2019.02.20